
一、性能优化需求
1)性能不足现象的产生:
a)前台访问很慢,请帮忙分析优化

b)用户对性能很不满意,再不解决就要投诉
c)数据库负载很重,请帮忙分析一下
d)XXX功能打开需要1分钟,请帮忙分析一下。
2)在接到这些性能优化要求的时候,运维工程师希望能够了解下面的信息以判断问题的类型,而通常情况下,大部分提出性能需求者都给不出这样的信息:
a)系统性的问题? 比如CPU利用率,SWAP利用率或者IO过高导致的整体性能下降?
b)功能性问题? 整体性能良好,个别功能时延很长
c)新出现问题?什么时候开始的,之前系统有哪些变动?(升级或者管理的资源大量增加)
d)不规律问题?有时候快,有时候慢,没有特定规律
还有性能快慢的衡量标准是什么? 原来多少秒,现在多少秒,目标是多少秒?只有上述问题得到了准确的回答,优化工作才能开始。
二、Linux性能分析
1、Linux性能分析的目的
1. 找出系统性能瓶颈(包括硬件瓶颈和软件瓶颈);
2. 提供性能优化的方案(升级硬件?改进系统系统结构?);
3. 达到合理的硬件和软件配置;
4. 使系统资源使用达到zui大的平衡;
一般情况下系统良好运行的时候恰恰各项资源达到了一个平衡体,任何一项资源的过渡使用都会造成平衡体系破坏,从而造成系统负载极高或者响应迟缓。
比如CPU过渡使用会造成大量进程等待CPU资源,系统响应变慢,等待会造成进程数增加,进程增加又会造成内存使用增加,内存耗尽又会造成虚拟内存使用,使用虚拟内存又会造成磁盘IO增加和CPU开销增加)。
2、性能分析的步骤
1)需要系统监控工具和性能分析工具
① 对资源的使用状况进行长期的监控和数据采集(nagios、cacti、ganglia、zabbix)
② 使用常见的性能分析工具(vmstat、top、htop、iotop、free、iostat等)
③ 实战技能和经验积累。
2)出现性能问题的可能原因
① 应用程序设计的缺陷和数据库查询的滥用zui有可能导致性能问题 。
② 性能瓶颈可能是因为程序差/内存不足/磁盘瓶颈,但zui终表现出的结果就是CPU耗尽,系统负载极高,响应迟缓,甚至暂时失去响应 。
③ 物理内存不够时会使用交换内存,使用swap会带来磁盘I0和cpu的开销。
④ 可能造成cpu瓶颈的问题:频繁执Perl,php,java程序生成动态web;数据库查询大量的where子句、order by/group by排序……
⑤ 可能造成内存瓶颈问题:高并发用户访问、系统进程多,java内存泄露……
⑥ 可能造成磁盘IO瓶颈问题:生成cache文件,数据库频繁更新,或者查询大表……
3、影响Linux性能的因素
1)CPU
CPU是操作系统稳定运行的根本,CPU的速度与性能在很大程度上决定了系统整体的性能,因此,CPU数量越多、主频越高,服务器性能也就相对越好。但事实并非完全如此。 目前大部分CPU在同一时间内只能运行一个线程,超线程的处理器可以在同一时间运行多个线程,因此,可以利用处理器的超线程特性提高系统性能。另外,Linux内核会把多核的处理器当作多个单独的CPU来识别,例如两个4核的CPU,在Lnux系统下会被当作8个单核CPU。但是从性能角度来讲,两个4核的CPU和8个单核的CPU并不完全等价,根据权威部门得出的测试结论,前者的整体性能要比后者低25%~30%。
可能出现CPU瓶颈的应用有邮件服务器、动态Web服务器等,对于这类应用,要把CPU的配置和性能放在主要位置。
2)内存
内存的大小也是影响Linux性能的一个重要的因素,内存太小,系统进程将被阻塞,应用也将变得缓慢,甚至失去响应;内存太大,导致资源浪费。Linux系统采用了物理内存和虚拟内存两种方式,虚拟内存虽然可以缓解物理内存的不足,但是占用过多的虚拟内存,应用程序的性能将明显下降,要保证应用程序的高性能运行,物理内存一定要足够大.
可能出现内存性能瓶颈的应用有redis内存数据库服务器、cache服务器、静态Web服务器等,对于这类应用要把内存大小放在主要位置。
3)磁盘I/O性能
磁盘的I/O性能直接影响应用程序的性能,在一个有频繁读写的应用中,如果磁盘I/O性能得不到满足,就会导致应用停滞。好在现今的磁盘都采用了很多方法来提高I/O性能,比如常见的磁盘RAID技术。
根据磁盘组合方式的不同,RAID可以分为RAID0,RAID1、RAID2、RAID3、RAID4、RAID5、RAID6、RAID7、RAID0+1、RAID10等级别,常用的RAID级别有RAID0、RAID1、RAID5、RAID0+1,这里进行简单介绍。
RAID 0:这种方式成本低,没有容错和数据修复功能,因而只能用在对数据安全性要求不高的环境中。
RAID 1:也就是磁盘镜像,通过把一个磁盘的数据镜像到另一个磁盘上,zui大限度地保证磁盘数据的可靠性和可修复性,具有很高的数据冗余能力,但磁盘利用率只有50%,因而,成本zui高,多用在保存重要数据的场合。
RAID5:采用了磁盘分段加奇偶校验技术,从而提高了系统可靠性,RAID5读出效率很高,写入效率一般,至少需要3块盘。允许一块磁盘故障,而不影响数据的可用性。
RAID0+1:把RAID0和RAID1技术结合起来就成了RAID0+1,至少需要4个硬盘。此种方式的数据除分布在多个盘上外,每个盘都有其镜像盘,提供全冗余能力,同时允许一个磁盘故障,而不影响数据可用性,并具有快速读/写能力。
通过了解各个RAID级别的性能,可以根据应用的不同特性,选择适合自身的RAID级别,从而保证应用程序在磁盘方面达到zui优性能。
目前常用的磁盘类型有STAT、SAS、SSD磁盘, STAT、SAS是普通磁盘,读写效率一般,如果要保证高性能的写操作,可采用SSD固态磁盘,读写速度可达600MB/s。
4)网络带宽
网络带宽也是影响性能的一个重要因素,低速的、不稳定的网络将导致网络应用程序的访问阻塞,而稳定、高速的网络带宽,可以保证应用程序在网络上畅通无阻地运行。幸运的是,现在的网络一般都是千兆带宽或光纤网络,带宽问题对应用程序性能造成的影响也在逐步降低。
组建网络时,如果局域网内有大量数据传输需求(hadoop大数据业务、数据库业务),可采用千兆、万兆网络接口,针对每个服务器,如果单网卡效率不够,可采用双网卡绑定技术,提高网卡数据传输带宽和性能。
5)系统安装
系统优化可以从安装操作系统开始,当安装Linux系统时,磁盘的划分,SWAP内存的分配都直接影响以后系统的运行性能,例如,磁盘分配可以遵循应用的需求:对于对写操作频繁而对数据安全性要求不高的应用,可以把磁盘做成RAID 0;而对于对数据安全性较高,对读写没有特别要求的应用,可以把磁盘做成RAID 1;对于对读操作要求较高,而对写操作无特殊要求,并要保证数据安全性的应用,可以选择RAID 5;对于对读写要求都很高,并且对数据安全性要求也很高的应用,可以选择RAID 01。这样通过不同的应用需求设置不同的RAID级别,在磁盘底层对系统进行优化操作。
随着内存价格的降低和内存容量的日益增大,对虚拟内存SWAP的设定,现在已经没有了所谓虚拟内存是物理内存两倍的要求,但是SWAP的设定还是不能忽略,根据经验,如果内存较小(物理内存小于4GB),一般设置SWAP交换分区大小为内存的2倍;如果物理内存大于8GB小于16GB,可以设置SWAP大小等于或略小于物理内存即可;如果内存大小在16GB以上,原则上可以设置SWAP为0,但并不建议这么做,因为设置一定大小的SWAP还是有一定作用的。
6)内核参数
系统安装完成后,优化工作并没有结束,接下来还可以对系统内核参数进行优化,不过内核参数的优化要和系统中部署的应用结合起来整体考虑。例如,如果系统部署的是Oracle数据库应用,那么就需要对系统共享内存段(kernel.shmmax、kernel.shmmni、kernel.shmall)、系统信号量(kernel.sem)、文件句柄(fs.file-max)等参数进行优化设置;如果部署的是Web应用,那么就需要根据Web应用特性进行网络参数的优化,例如修改net.ipv4.ip_local_port_range、net.ipv4.tcp_tw_reuse、net.core.somaxconn等网络内核参数。
7)文件系统
文件系统的优化也是系统资源优化的一个重点,在Linux下可选的文件系统有ext3、ext4、xfs,根据不同的应用,选择不同的文件系统。
Linux标准文件系统是从VFS开始的,然后是ext,接着就是ext2,应该说,ext2是Linux上标准的文件系统,ext3是在ext2基础上增加日志形成的,从VFS到ext4,其设计思想没有太大变化,都是早期UNIX家族基于超级块和inode的设计理念。
4、性能分析标准
性能调优的主要目的是使系统能够有效的利用各种资源,zui大的发挥应用程序和系统之间的性能融合,使应用高效、稳定的运行。但是,衡量系统资源利用率好坏的标准没有一个严格的定义,针对不同的系统和应用也没有一个统一的说法,因此,这里提供的标准其实是一个经验值,下面给出了判定系统资源利用状况的一般准则:
影响性能因素 | 评判标准 | ||
好 | 坏 | 糟糕 | |
CPU | user% + sys%< 70% | user% + sys%= 85% | user% + sys% >=90% |
内存 | Swap In(si)=0 Swap Out(so)=0 | Per CPU with 10 page/s | More Swap In & Swap Out |
磁盘 | iowait % < 20% | iowait % =35% | iowait % >= 50% |
其中:
%user:表示CPU处在用户模式下的时间百分比。 %sys:表示CPU处在系统模式下的时间百分比。 %iowait:表示CPU等待输入输出完成时间的百分比。 swap in:即si,表示虚拟内存的页导入,即从SWAP DISK交换到RAM。 swap out:即so,表示虚拟内存的页导出,即从RAM交换到SWAP DISK。三、系统性能评估与分析工具
1、性能分析工具简介
1)vmstat
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,很多linux发行版本都默认安装了此命令工具,利用vmstat命令可以对操作系统的内存信息、进程状态、CPU活动等进行监视,不足之处是无法对某个进程进行深入分析。
vmstat使用语法如下:
vmstat [-V] [-n] [delay [count]] 各个选项及参数含义如下:
-V:表示打印出版本信息,是可选参数。 -n:表示在周期性循环输出时,输出的头部信息仅显示一次。 delay:表示两次输出之间的间隔时间。 count:表示按照“delay”指定的时间间隔统计的次数。默认为1。 例如: vmstat 3:表示每3秒钟更新一次输出信息,循环输出,按ctrl+c停止输出。 vmstat 3 5:表示每3秒更新一次输出信息,统计5次后停止输出。2)iostat命令
iostat是I/O statistics(输入/输出统计)的缩写,主要的功能是对系统的磁盘I/O操作进行监视。它的输出主要显示磁盘读写操作的统计信息,同时也会给出CPU使用情况。同vmstat一样,iostat也不能对某个进程进行深入分析,仅对系统的整体情况进行分析。
iostat一般都不随系统安装,要使用iostat工具,需要在系统上安装一个Sysstat的工具包,Sysstat是一个开源软件,官方地址为http://pagesperso-orange.fr/sebastien.godard 安装完毕,系统会多出3个命令:iostat、sar和mpstat。然后就可以直接在系统下运行iostat命令了。
iostat使用语法如下:
iostat [ -c | -d ] [ -k ] [ -t ] [ -x [ device ] ] [ interval [ count ] ] 各个选项及参数含义如下:
-c:显示CPU的使用情况。 -d:显示磁盘的使用情况。 -k:每秒以k bytes为单位显示数据。 -t:打印出统计信息开始执行的时间。 -x device:指定要统计的磁盘设备名称,默认为所有的磁盘设备。 interval:指定两次统计间隔的时间; count:按照“interval”指定的时间间隔统计的次数。3)sar命令
sar命令很强大,是分析系统性能的重要工具之一,通过sar指令,可以全面的获取系统的CPU、运行队列、磁盘I/O、分页(交换区)、内存、CPU中断、网络等性能数据。
sar使用格式为:
sar [options] [-o filename] [interval [count] ] 各个选项及参数含义如下:
options 为命令行选项,sar命令的选项很多,下面只列出常用选项:
-A:显示系统所有资源设备(CPU、内存、磁盘)的运行状况。 -u:显示系统所有CPU在采样时间内的负载状态。 -P:显示当前系统中指定CPU的使用情况。 -d:显示系统所有硬盘设备在采样时间内的使用状况。 -r:显示系统内存在采样时间内的使用状况。 -b:显示缓冲区在采样时间内的使用情况。 -v:显示进程、文件、I节点和锁表状态。 -n:显示网络运行状态。参数后面可跟DEV、EDEV、SOCK和FULL。DEV显示网络接口信息,EDEV显示网络错误的统计数据,SOCK显示套接字信息,FULL显示三个所有的信息。它们可以单独或者一起使用。 interval:表示采样间隔时间,是必须有的参数。 count:表示采样次数,是可选参数,默认值是1。2、CPU性能评估
1)vmstat
该命令可以显示关于系统各种资源之间相关性能的简要信息,这里我们主要用它来看CPU的一个负载情况。
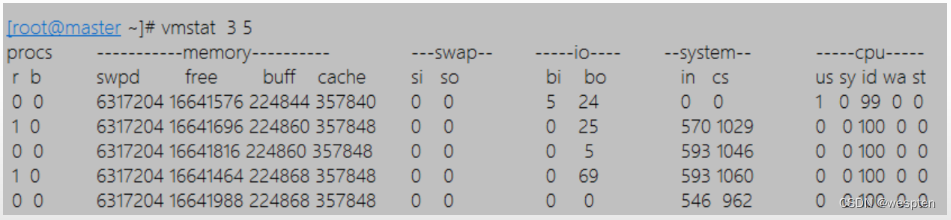
对上面每项的输出解释如下:
Procs: r列表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的核数的2-4倍,说明CPU不足,需要增加CPU。 b列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等 Memory: swpd列表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si、so的值长期为0,这种情况下一般不用担心,不会影响系统性能。 free列表示当前空闲的物理内存数量(以k为单位) buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。 cache列表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。 swap:si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。 so列表示由内存调入磁盘,也就是内存交换区进入内存的数量。 一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足。需要增加系统内存。 IO项显示磁盘读写状况:Bi列表示从块设备读入数据的总量(即读磁盘)(每秒kb)。 Bo列表示写入到块设备的数据总量(即写磁盘)(每秒kb) 这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大,则表示系统磁盘IO有问题,应该考虑提高磁盘的读写性能。 system: 显示采集间隔内发生的中断数,in列表示在某一时间间隔中观测到的每秒设备中断数。 cs列表示每秒产生的上下文切换次数。 上面这2个值越大,会看到由内核消耗的CPU时间会越多。 CPU项显示了CPU的使用状态:此列是我们关注的重点,us列显示了用户进程消耗的CPU 时间百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法。 sy列显示了内核进程消耗的CPU时间百分比。Sy的值较高时,说明内核消耗的CPU资源很多。 根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。 id 列显示了CPU处在空闲状态的时间百分比。 wa列显示了IO等待所占用的CPU时间百分比。wa值越高,说明IO等待越严重,根据经验,wa的参考值为20%,如果wa超过20%,说明IO等待严重,引起IO等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者磁盘控制器的带宽瓶颈造成的(主要是块操作)。 综上所述,在对CPU的评估中,需要重点注意的是procs项r列的值和CPU项中us、sy和id列的值。
2)sar
下面是sar命令对某个系统的CPU统计输出:
[root@webserver ~]# sar -u 3 5 Linux 2.6.9-42.ELsmp (webserver) 11/28/2008 _i686_ (8 CPU) 11:41:24 AM CPU %user %nice %system %iowait %steal %idle 11:41:27 AM all 0.88 0.00 0.29 0.00 0.00 98.83 11:41:30 AM all 0.13 0.00 0.17 0.21 0.00 99.50 11:41:33 AM all 0.04 0.00 0.04 0.00 0.00 99.92 对上面每项的输出解释如下:
%user列显示了用户进程消耗的CPU 时间百分比。 %nice列显示了运行正常进程所消耗的CPU 时间百分比。 %system列显示了系统进程消耗的CPU时间百分比。 %iowait列显示了IO等待所占用的CPU时间百分比。 %steal列显示了在内存相对紧张的环境下pagein强制对不同的页面进行的steal操作。 %idle列显示了CPU处在空闲状态的时间百分比。 这个输出是对系统整体CPU使用状况的统计,每项的输出都非常直观,并且zui后一行Average是个汇总行,是上面统计信息的一个平均值。
需要注意的一点是:第一行的统计信息中包含了sar本身的统计消耗,所以%user列的值会偏高一点,不过,这不会对统计结果产生多大影响。
在一个多CPU的系统中,如果程序使用了单线程,会出现这么一个现象,CPU的整体使用率不高,但是系统应用却响应缓慢,这可能是由于程序使用单线程的原因,单线程只使用一个CPU,导致这个CPU占用率为100%,无法处理其它请求,而其它的CPU却闲置,这就导致了整体CPU使用率不高,而应用缓慢现象的发生。
3)iostat
iostat指令主要用于统计磁盘IO状态,但是也能查看CPU的使用信息,它的局限性是只能显示系统所有CPU的平均信息,看下面的一个输出:
[root@webserver ~]# iostat -c Linux 2.6.9-42.ELsmp (webserver) 11/29/2008 _i686_ (8 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 2.52 0.00 0.30 0.24 0.00 96.96 在这里,我们使用了“-c”参数,只显示系统CPU的统计信息,输出中每项代表的含义与sar命令的输出项完全相同。
4)uptime
uptime是监控系统性能zui常用的一个命令,主要用来统计系统当前的运行状况,输出的信息依次为:系统现在的时间、系统从上次开机到现在运行了多长时间、系统目前有多少登陆用户、系统在一分钟内、五分钟内、十五分钟内的平均负载。
看下面的一个输出:
[root@webserver ~]# uptime 18:52:11 up 27 days, 19:44, 2 users, load average: 0.12, 0.08, 0.08这里需要注意的是load average这个输出值,这三个值的大小一般不能大于系统CPU的核数,例如,本输出中系统有8个CPU,如果load average的三个值长期大于8时,说明CPU很繁忙,负载很高,可能会影响系统性能,但是偶尔大于8时,倒不用担心,一般不会影响系统性能。相反,如果load average的输出值小于CPU的个数,则表示CPU还有空闲的时间片,比如本例中的输出,CPU是非常空闲的。
5)htop
它类似于 top 命令,但可以让你在垂直和水平方向上滚动,所以你可以看到系统上运行的所有进程,以及他们完整的命令行。可以不用输入进程的 PID 就可以对此进程进行相关的操作。
Htop的安装,既可以通过源码包编译安装,也可以配置好yum源后网络下载安装,推荐yum方式安装,但是要下载一个epel源,因为htop包含在epel源中。安装很简单,命令如下:
yum install -y htop安装完成后,命令行中直接敲击htop命令,即可进入htop的界面。
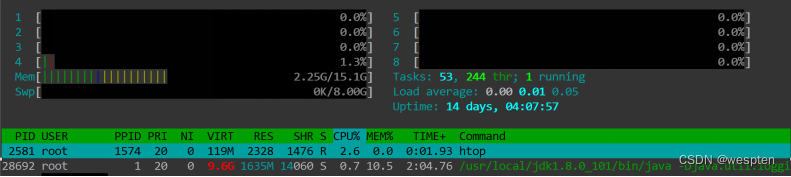
各项从上至下分别说明如下:
左边部分从上至下,分别为,cpu、内存、交换分区的使用情况,右边部分为:Tasks为进程总数,当前运行的进程数、Load average为系统1分钟,5分钟,10分钟的平均负载情况、Uptime为系统运行的时间。
3、内存性能评估与分析工具
1)free
free是监控linux内存使用状况zui常用的指令,看下面的一个输出:

“free –m”表示以M为单位查看内存使用情况。
一般有这样一个经验公式:应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能,应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存,20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
2)vmstat
vmstat命令在监控系统内存方面功能强大,请看下面的一个输出:
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 0 0 906440 22796 155616 1325496 340 180 2 4 1 4 80 0 10 10 0 0 906440 42796 155616 1325496 320 289 0 54 1095 287 70 15 0 15 0 0 906440 42884 155624 1325748 236 387 2 102 1064 276 78 2 5 15 对于内存的监控,在vmstat中重点关注的是swpd、si和so行,从这个输出可以看出,此系统内存资源紧缺,swpd占用了900M左右内存,si和so占用很大,而由于系统内存的紧缺,导致出现15%左右的系统等待,此时增加系统的内存是必须要做的。
3)Smem
Smem是一款命令行下的内存使用情况报告工具,它能够给用户提供 Linux 系统下的内存使用的多种报告。和其它传统的内存报告工具不同的是,它有个独特的功能,可以报告 PSS。
Linux使用到了虚拟内存(virtual memory),因此要准确的计算一个进程实际使用的物理内存就不是那么简单。只知道进程的虚拟内存大小也并没有太大的用处,因为还是无法获取到实际分配的物理内存大小。
RSS(Resident set size),使用top命令可以查询到,是zui常用的内存指标,表示进程占用的物理内存大小。但是,将各进程的RSS值相加,通常会超出整个系统的内存消耗,这是因为RSS中包含了各进程间共享的内存。
PSS(Proportional set size)所有使用某共享库的程序均分该共享库占用的内存时。显然所有进程的PSS之和就是系统的内存使用量。它会更准确一些,它将共享内存的大小进行平均后,再分摊到各进程上去。
USS(Unique set size )进程独自占用的内存,它只计算了进程独自占用的内存大小,不包含任何共享的部分。
安装Smem
首先启用 EPEL (Extra Packages for Enterprise Linux)软件源,然后按照下列步骤操作:
yum install smem python-matplotlib python-tk 以百分比的形式报告内存使用情况:
smem -p每一个用户的内存使用情况:
smem -u查看某个进程占用内存大小:
smem -P nginx smem -k -P nginx4、磁盘I/O性能评估与分析工具
1)iostat
在对磁盘I/O性能做评估之前,必须知道的几个方面是:
(1)尽可能用内存的读写代替直接磁盘I/O,使频繁访问的文件或数据放入内存中进行操作处理,因为内存读写操作比直接磁盘读写的效率要高千倍。
(2)将经常进行读写的文件与长期不变的文件独立出来,分别放置到不同的磁盘设备上。
(3)对于写操作频繁的数据,可以考虑使用裸设备代替文件系统。
iostat -d 命令组合:
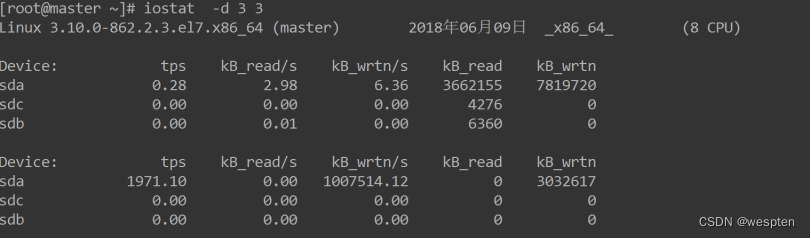
对上面每项的输出解释如下:
Blk_read/s表示每秒读取的数据块数。 Blk_wrtn/s表示每秒写入的数据块数。 Blk_read表示读取的所有块数。 Blk_wrtn表示写入的所有块数。 这里需要注意的一点是:上面输出的第一项是系统从启动以来到统计时的所有传输信息,从第二次输出的数据才代表在检测的时间段内系统的传输值。
可以通过Blk_read/s和Blk_wrtn/s的值对磁盘的读写性能有一个基本的了解,如果Blk_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或者优化程序,如果Blk_read/s值很大,表示磁盘直接读取操作很多,可以将读取的数据放入内存中进行操作。对于这两个选项的值没有一个固定的大小,根据系统应用的不同,会有不同的值,但是有一个规则还是可以遵循的:长期的、超大的数据读写,肯定是不正常的,这种情况一定会影响系统性能。
2)iotop
iotop是一个用来监视磁盘I/O使用状况的top类工具,可监测到哪一个程序使用的磁盘IO的实时信息,可直接执行yum在线安装:
yum -y install iotop常用选项:
-p 指定进程ID,显示该进程的IO情况。 -u 指定用户名,显示该用户所有的进程IO情况。 -P, --processes,只显示进程,默认为显示所有的线程。 -k, --kilobytes,以千字节显示。 -t, --time,在每一行前添加一个当前的时间。输出详情:

交互模式下的排序按键:
o键是只显示有IO输出的进程。
左右箭头改变排序方式,默认是按IO排序。
p键,可进行线程、进程切换。
5、网络性能评估与分析工具
1)ping
如果发现网络反应缓慢,或者连接中断,可以通过ping来测试网络的连通情况,请看下面的一个输出:
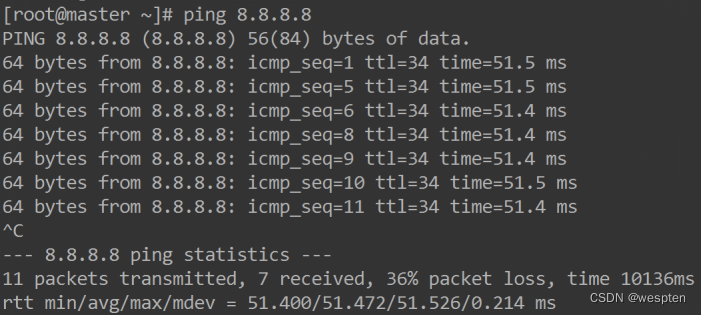
在这个输出中,time值显示了两台主机之间的网络延时情况,如果此值很大,则表示网络的延时很大,单位为毫秒。在这个输出的zui后,是对上面输出信息的一个总结,packet loss表示网络的丢包率,此值越小,表示网络的质量越高。
2)netstat
netstat命令提供了网络接口的详细信息,请看下面的输出:

输出项说明:
Iface表示网络设备的接口名称。 MTU表示zui大传输单元,单位字节。 RX-OK/TX-OK表示已经准确无误的接收/发送了多少数据包。 RX-ERR/TX-ERR表示接收/发送数据包时产生了多少错误。 RX-DRP/TX-DRP表示接收/发送数据包时丢弃了多少数据包。 RX-OVR/TX-OVR表示由于误差而遗失了多少数据包。 Flg表示接口标记,其中:
L:表示该接口是个回环设备。 B:表示设置了广播地址。 M:表示接收所有数据包。 R:表示接口正在运行。 U:表示接口处于活动状态。 O:表示在该接口上禁用arp。 P:表示一个点到点的连接。正常情况下,RX-ERR/TX-ERR、RX-DRP/TX-DRP和RX-OVR/TX-OVR的值都应该为0,如果这几个选项的值不为0,并且很大,那么网络质量肯定有问题,网络传输性能也一定会下降。
3)tcpdump
tcpdump 可以将网络中传送的数据包的header完全截获下来进行分析,它支持对网络层(net IP 段)、协议(TCP/UDP)、主机(src/dst host)、网络或端口(prot)的过滤,并提供and、or、not等逻辑语句来去掉无用的信息。
tcpdump的常用选项如下:
-i :指定网卡 默认是 eth0。 -n :线上ip,而不是hostname。 -c :指定抓到多个包后推出。 -A:以ASCII方式线上包的内容,这个选项对文本格式的协议包很有用。 -x:以16进制显示包的内容。 -vvv:显示详细信息。 -s :按包长截取数据;默认是60个字节;如果包大于60个字节,则抓包会出现丢数据;所以一般会设置 -s 0 。这样会按照包的大小截取数据;抓到的是完整的包数据。 -r:从文件中读取【与 -w 对应,/usr/sbin/tcpdump -r test.out 读取 tcpdump -w test.out 】。 -w:指定一个文件,保存抓包信息到此文件中,推荐使用这个选项,-w t.out ,然后用 -r t.out 来看抓包信息,否则,数据包信息太多,可读性很差。 抓取所有经过eth0的网络数据:
tcpdump -i eth0 tcpdump -n -i eth0 抓取所有经过eth0的5个数据包:
tcpdump -c 5 -i eth0 抓取所有经过 eth0,基于tcp协议的网络数据:
tcpdump -i eth0 tcp 抓取所有经过 eth0,目的或源端口是22的网络数据:
tcpdump -i eth0 port 22抓取所有经过 eth0,源地址是192.168.0.2的网络数据:
tcpdump -i eth0 src 192.168.0.2 抓取所有经过eth0,目的地址是50.116.66.139的网络数据:
tcpdump -i eth0 dst 50.116.66.139 将抓取所有经过eth0网卡的数据写到0001.pcap文件中:
tcpdump -w 0001.pcap -i eth0 从0001.pcap文件中读取抓取的数据包:
tcpdump -r 0001.pcaptcpmdump抓包出来后要分析包的具体含义,常见的包携带的标志有:
S:S=SYC :发起连接标志。 P:P=PUSH:传送数据标志。 F:F=FIN:关闭连接标志。 ack:表示确认包。 RST=RESET:异常关闭连接 . 表示没有任何标志。 6、Web应用性能优化案例
1)动态网站优化案例
硬件环境:两台IBM x3850服务器, 两个双核Intel(R) Xeon(R) CPU E5620,64GB内存,2块1TB STAT磁盘做系统盘。两块2TB磁盘做数据盘。
操作系统:CentOS6.9 x86_64。
网站架构:Web应用是基于J2EE架构的电子商务应用,Web端应用服务器是Tomcat,采用MySQL数据库,Web和数据库独立部署在两台服务器上。
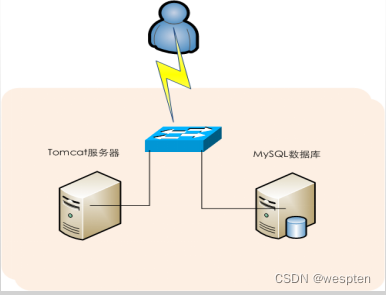
现象描述:网站访问高峰时,网页无法打开,重启tomcat服务后,网站可以正常运行一段时间,但过一会又变得响应缓慢,zui后网页彻底无法打开。
检查配置:首先检查系统资源状态,发现服务出现故障时系统负载极高,CPU满负荷运行,Java进程占用了系统99%的CPU资源,但内存资源占用不大;接着检查应用服务器信息,发现只有一个Tomcat在运行Java程序;接着查看Tomcat配置文件server.xml,发现server.xml文件中的参数都是默认配置,没有进行任何优化。
处理措施:server.xml文件的默认参数需要根据应用的特性进行适当的修改,例如可以修改“connectionTimeout“、“maxKeepAliveRequests”、“maxProcessors”等几个Tmcat配置文件的参数,适当加大这几个参数值。
修改参数值后,继续观察发现,网站服务宕机时间间隔加长了,不像以前那么频繁,但是Java进程消耗CPU资源还是很严重,网页访问速度极慢。
Tomcat JVM参数优化
修改TOMCAT_HOME/bin/catalina.sh,增加如下内容:
JAVA_OPTS=“-server -Xms3550m -Xmx3550m -Xmn1g -XX:PermSize=256M -XX:MaxPermSize=512m” export JAVA_OPTS 整个堆内存大小 = 年轻代大小 + 年老代大小 + 持久代大小
-Xmx3550m:设置JVMzui大堆内存 为3550M。
-Xms3550m:设置JVM初始堆内存 为3550M。
-Xmn1g:设置堆内存年轻代 大小为1G。
整个堆内存大小 = 年轻代大小 + 年老代大小 + 持久代大小。
持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小,此值对系统性能影响较大 。
-XX:PermSize=256M:设置堆内存持久代初始值为256M。
-XX:MaxPermSize=512M:设置持久代zui大值为512M。
原因分析:
既然Java进程消耗CPU资源严重,那么需要查看到底是什么导致Java消耗资源严重,通过lsof、netstat命令发现有大量的Java请求等待信息,然后查看Tomcat日志,发现大量报错信息、日志提示和数据库连接超时,zui终无法连接到数据库,同时,访问网站静态资源,也无法访问。
于是得出如下结论:
Tomcat本身就是一个Java容器,是使用连接/线程模型处理业务请求的,主要用于处理Jsp、servlet等动态应用,虽然它也能当作HTTP服务器,但是处理静态资源的效率很低,远远比不上Apache或Nginx。从前面观察到的现象分析,可以初步判断是Tomcat无法及时响应客户端的请求,进而导致请求队列越来越多,直到Tomcat彻底崩溃。
处理措施:
要优化Tomcat性能,需要从结构上进行重构,首先,加入Apache支持,由Apache处理静态资源,由Tomcat处理动态请求,Apache服务器和Tomcat服务器之间使用Mod_JK模块进行通信。
第二次分析优化
经过前面的优化措施,Java资源偶尔会增高,但是一段时间后又会自动降低,这属于正常状态,而在高并发访问情况下,Java进程有时还会出现资源上升无法下降的情况。
通过查看Tomcat日志,综合分析得出如下结论:
要获得更高、更稳定的性能,单一的Tomcat应用服务器有时会无法满足需求,因此要结合Mod_JK模块运行基于Tomcat的负载均衡系统,这样前端由Apache负责用户请求的调度,后端又多个Tomcat负责动态应用的解析操作,通过将负载均分配给多个Tomcat服务器,网站的整体性能会有一个质的提升。
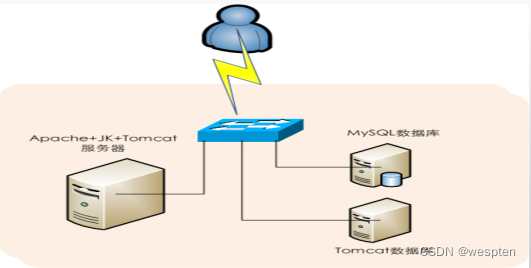
2)Tomcat占用CPU超高的解决思路与方法
java中进程与线程的概念
进程是程序的一次动态执行,它对应着从代码加载,执行至执行完毕的一个完整的过程,是一个动态的实体,它有自己的生命周期。它因创建而产生,因调度而运行,因等待资源或事件而被处于等待状态,因完成任务而被撤消。
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行。
进程和线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)进程作为资源分配的zui小单位,资源是分配给进程的,同一进程的所有线程共享该进程的所有资源。
(3)真正在处理机上运行的是线程。 进
程与线程的区别:
(1)调度:线程作为调度和分配的基本单位,进程作为拥有资源的基本单位。
(2)并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行。
(3)拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源。
(4)系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。
Tomcat底层是通过JVM运行的,JVM在操作系统中是作为一个进程存在的,而java中的所有线程在JVM进程中,但是CPU调度的是进程中的线程。因此,java是支持多线程的,体现在操作系统中,就是java进程可以使用CPU的多核资源。
现象描述:
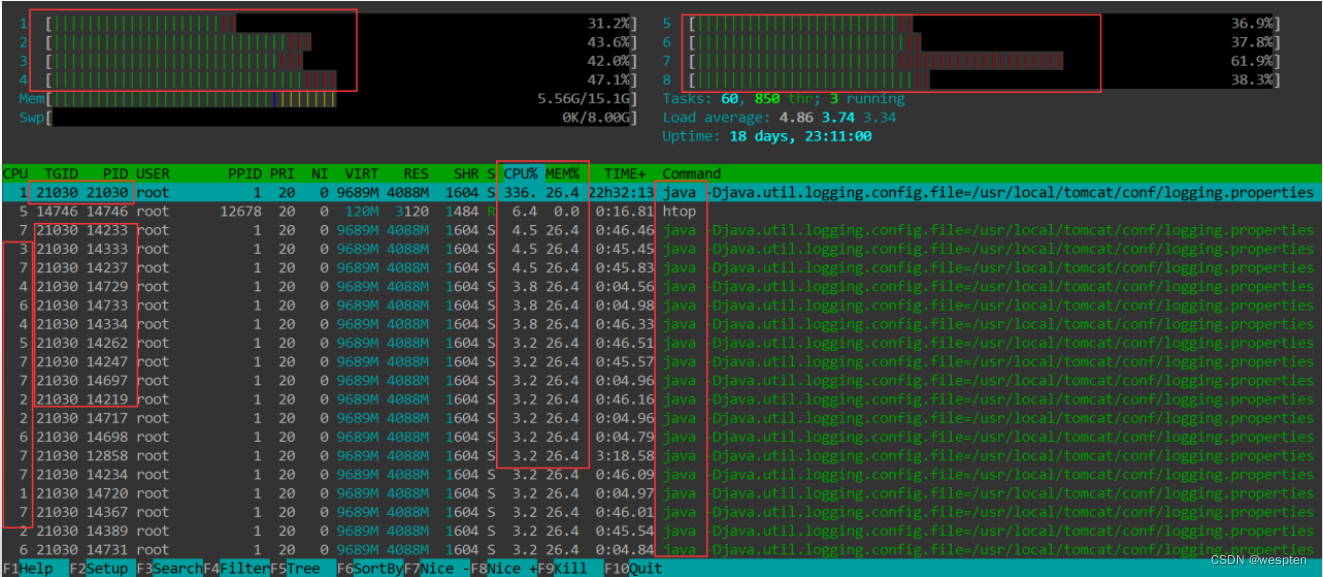
排查java进程占用CPU过高的思路:
(1)提取占用CPU过高的进程
方法一:使用top或htop命令查找到占用CPU高的进程的pid:
top -d 1 方法二:使用ps查找到tomcat运行的进程pid:
ps -ef | grep tomcat (2)、定位有问题的线程的pid
根据上面第一步拿到的pid号,执行“top -H -p pid”命令 。然后按下shift+p,查找出cpu利用率zui厉害的线程号。
(3)将线程的pid转换为16进制数 printf ‘%x\n’ pid 注意,此处的pid为上一步找到的占CPU高的线程的PID。
(4)使用jstack工具将进程信息打印输出 用jstack打印线程信息 ,将信息重定向到文件中。
执行如下操作:
jstack pid |grep tid 例如:
jstack 30116 | grep -A 20 75cf 或
jstack 30116 |grep 75cf >> jstack.out这里的“75cf “就是线程的pid转换为16进制数的结果。
(5)根据输出信息进行具体分析
四、CPU-内存-IO-网络调优
1、CPU性能调优
1)CPU处理方式
1. 批处理,顺序处理请求。(切换次数少,吞吐量大)。
批处理 - 以前的大型机(Mainframe)上所采用的系统,需要把一批程序事先写好(打孔纸带),然后计算得出结果 。
2. 分时处理。(如同"独占",吞吐量小)(时间片,把请求分为一个一个的时间片,一片一片的分给CPU处理)我们现在使用x86就是这种架构。
分时 - 现在流行的PC机和服务器都是采用这种运行模式,即把CPU的运行分成若干时间片分别处理不同的运算请求。
3. 实时处理
实时 - 一般用于单片机上,比如电梯的上下控制,对于按键等动作要求进行实时处理。
2)查看CPU一分钟有多个切换多少次
查看内核一秒钟中断CPU次数:
[root@localhost ~]# grep HZ /boot/config-3.10.0-693.el7.x86_64 CONFIG_NO_HZ=y # CONFIG_HZ_100 is not set # CONFIG_HZ_250 is not set # CONFIG_HZ_300 is not set CONFIG_HZ_1000=y CONFIG_HZ=1000 #1秒钟有1000次中断此文件/boot/config-3.10.0-693.el7.x86_64 是编译内核的参数文件。
3)调整进程优先级使用更多CPU
调整进程nice值,让进程使用更多的CPU。
nice值范围:-20 ~ 19越小优先级越高,普通用户0-19。
nice作用:以什么优先级运行进程 。默认优先级是0。
语法:
nice -n 优先级数字例如:
# nice -n -5 vim a.txt # vim进程以-5级别运行查看:
ps -axu | grep a.txt [root@localhost ~]# ps -axu | grep a.txt Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ root 24318 0.0 0.2 143624 3280 pts/4 S+ 17:00 0:00 vim b.txt [root@localhost ~]# top -p 24318 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24129 root 15 -5 140m 3336 2200 S 0.0 0.3 0:00.08 vim renice修改正在运行的进程的优先级:
#renice -n 5 PID #修改进程优先级例如:
#renice -n 5 24318 [root@xuegod63 ~]# top -p 24318 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24129 root 15 5 140m 3336 2200 S 0.0 0.3 0:00.08 vim 检测一下范围:-20-19:
[root@xuegod63 ~]# renice -n -21 24129 24129: old priority 5, new priority -20 [root@xuegod63 ~]# renice -n 20 24129 24129: old priority -20, new priority 194)CPU亲和力
taskset 作用:在多核情况下,可以认为指定一个进程在哪颗CPU上执行程序,减少进程在不同CPU之前切换的开销。
安装:
[root@localhost ~]# rpm -qf `which taskset ` util-linux-2.23.2-43.el7.x86_64语法:
taskset -c N 命令本机是4核CPU ,指定vim命令在第一个CPU上运行:
[root@localhost ~]# taskset -c 0 vim a.txt #1号CPU ID是0 [root@localhost ~]# ps -axu | grep vim Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ root 2614 1.3 0.2 143696 3332 pts/0 S+ 18:39 0:00 vim a.txt [root@localhost ~]# taskset -p 2614 # -p 要查看的进程ID pid 2614's current affinity mask: 1 #CPU亲和力掩码,1代表第一个CPU核心查sshd进程运行在哪几个CPU上:
[root@localhost ~]# ps -axu | grep sshd Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ root 2030 0.0 0.0 64068 1140 ? Ss 18:26 0:00 /usr/sbin/sshd [root@localhost ~]# taskset -p 2030 pid 2030's current affinity mask: f #说明sshd在4颗CPU上随机进行切换。cpu ID号码,对应的16进制数为:
CPU ID: 7 6 5 4 3 2 1 0 对应的10数为: 128 64 32 16 8 4 2 1 当前, 我的系统中cpu ID的为(0、1、2、3) 。pid 2030's current affinity mask: f的值为cpu ID 16进制的值的和(1+2+4+8=f),转换成二进制为:1111。
这个说明了(pid=2030)的这个sshd进程工作在cpu ID 分别为0,1,2,3这个四个cpu上面的切换。
我们的CPU是4核心,所以taskset -c后可以跟 0、1、2、3。
指定vim c.txt 程序运行在第2和第4个CPU上:
[root@localhost ~]# taskset -c 1,3 vim b.txt [root@localhost ~]# ps -axu | grep vim Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ root 6314 1.5 0.2 143612 3280 pts/1 S+ 14:41 0:00 vim b.txt root 6317 0.0 0.0 103300 848 pts/2 S+ 14:41 0:00 grep vim [root@localhost ~]# taskset -p 6314 pid 6314's current affinity mask: a # a为十进制的10=2+8 注:在哪个CPU上运行,那一位就赋为1 。
5)CPU 性能监控
理解运行队列,利用率,上下文切换对怎样CPU 性能zui优化之间的关系,早期提及到性能是相对于基准线数据的,在一些系统中,通常预期所达到的性能包括:
Run Queues 每个处理器应该运行队列不超过13个线程比如一个双核处理器应该运行队列不要超过6 个。
注:有两个特殊的进程永远在运行队列中待着,当前进程和空进程idle。
6)CPU 利用率比例分配
如果一个CPU 被充分使用,利用率分类之间均衡的比例应该是:
65% 70% User Time #用户态 30% 35% System Time #内核态 0% 5% Idle Time #空闲 Context Switches #上下文切换的数目直接关系到CPU 的使用率,如果CPU 利用率保持在上述均衡状态时,有大量的上下文切换是正常的。实例1:持续的CPU 利用率:
[root@localhost ~]# vmstat 1 10 # 本机为单核CPU,执行vmstat显示以下内容 procs --------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 3 0 0 130644 86244 609860 0 0 4 1 531 25 0 0 20 0 0 4 0 0 130620 86244 609860 0 0 0 0 638 62 0 0 14 0 0 2 0 0 130620 86244 609860 0 0 0 0 658 62 0 0 13 0 0 4 0 0 130620 86244 609860 0 0 0 0 688 62 0 0 11 0 0在这个例子中,这个系统的CPU被充分利用。
根据观察值,我们可以得到以下结论:
1、有大量的中断(in) 和较少的上下文切换(cs)。这意味着一个单一的进程正在大量使用cpu
2、进一步显示某单个应用,user time(us) 经常在86%或者更多。
执行top -》按P-》查看使用CPUzui多的进程
3、运行队列还在可接受的性能范围内,其中有2个地方,是超出了允许限制.
实例2:超负荷调度:
# vmstat 1 #通过查看vmstat输出结果,分析当前系统中出现的问题 procs memory swap io system cpu r b swpd free buff cache si so bi bo in cs us sy wa id 2 1 207740 98476 81344 180972 0 0 2496 0 900 2883 4 12 57 27 0 1 207740 96448 83304 180984 0 0 1968 328 810 2559 8 9 83 0 0 1 207740 94404 85348 180984 0 0 2044 0 829 2879 9 6 78 7 0 1 207740 92576 87176 180984 0 0 1828 0 689 2088 3 9 78 10 2 0 207740 91300 88452 180984 0 0 1276 0 565 1282 7 6 83 4 3 1 207740 90124 89628 180984 0 0 1176 0 551 1229 2 7 91 0在这个例子中,内核调度中的上下文切换处于饱和。
根据观察值,我们可以得到以下结论:
1、上下文切换数目高于中断数目,说明kernel中相当数量的时间都开销在:上下文切换线程。
2、大量的上下文切换将导致CPU 利用率不均衡,很明显实际上等待io 请求的百分比(wa)非常高,以及user time百分比非常低(us). 说明磁盘比较慢,磁盘是瓶颈。
3、因为CPU 都阻塞在IO请求上,所以运行队列里也有相当数个的可运行状态线程在等待执行。
2、内存性能调优
1)内存调优相关内容
关于内存,一般情况不用调优,我们在这里分析一些情况:
BUFFER inode节点索引缓存 缓存 写时用,先写入到内存 CACHE block块/页缓存 快取 读时用,先读入到内存 buffers #缓存从磁盘读出的内容,这种理解是片面的 cached #缓存需要写入磁盘的内容,这种理解是片面的buffer:
free -h Or vmstat 终端2:find / 终端1: free -m #查看buffer增长cache:
free -m Or vmstat 终端2:grep aaaa / -R 终端1: free -m #查看CAHCE增长说明:
CACHE:页缓存,内存页 一页尺寸 4KB 对象文件系统块block: 1kB 2kB 4kB 扇区sectors: 512b2)手动清空buffer+cache
[root@localhost ~]# cat /proc/sys/vm/drop_caches #默认是 0 0 [root@localhost ~]# free -m [root@localhost ~]# free total used free shared buff/cache available Mem: 999720 290728 367972 7396 341020 495424 Swap: 2097148 0 2097148 [root@apache ~]# sync # 把内存中的数据写入磁盘 [root@localhost ~]# echo 1 > /proc/sys/vm/drop_caches [root@localhost ~]# free -m total used free shared buff/cache available Mem: 976 283 484 7 208 495 Swap: 2047 0 20473、磁盘I/O性能调优
1)资源限制
限制用户资源配置文件:
vim /etc/security/limits.conf每行的格式:
用户名/@用户组名 类型(软限制/硬限制) 选项 值 永久修改一个进程可以打开的zui大文件数:
vim /etc/security/limits.conf #在zui添加: * soft nofile 1024000 * hard nofile 1024000 reboot #永久生效的缺点,必须重启系统soft是一个警告值,而hard则是一个真正意义的阀值,超过就会报错。soft一定要比hard小,zui大打开的文件数(以文件描叙符,file descripter计数。
检查:
root@localhost ~]# ulimit -n 1024000 [root@localhost ~]# useradd kill #以普通用户登录,测试 [root@localhost ~]# su - kill [mkkk@localhost ~]$ ulimit -n 1024000 方法二:#临时修改 [root@localhost ~]# ulimit -n 10000 [root@localhost ~]# ulimit -n 10000/etc/security/limits.conf是模块pam_limits.so的配置文件。
pam相关配置文件:
/lib64/security/ #pam模块所在目录 /etc/security/ #pam每个模块的配置文件 /etc/pam.d/ #使用pam功能的服务和应用程序的配置文件通过pam_limits.so 模块查看系统中哪些应用程序和服务使用了:
[root@localhost ~]# grep pam_limits.so /etc/pam.d/ -R ... /etc/pam.d/system-auth:session required pam_limits.so用户可以打开的zui大进程数:
[root@localhost ~]# vim /etc/security/limits.d/90-nproc.conf #RHEL6 必须这个文件中配置 改: * soft nproc 10240 为: * soft nproc 66666 * hard nproc 66666 [root@localhost ~]# reboot #更好重启一下 [root@localhost ~]# ulimit -u 66666 临时:
[root@localhost ~]# ulimit -u 60000 [root@localhost ~]# ulimit -u 60000默认用户可用的zui大进程数量1024.这样以apache用户启动的进程就数就不能大于1024了。
[root@apache ~]# ulimit -a core file size (blocks, -c) 0 kdump转储功能打开后产生的core file大小限制 data seg size (kbytes, -d) unlimited 数据段大小限制 scheduling priority (-e) 0 file size (blocks, -f) unlimited 文件大小限制 pending signals (-i) 27955 max locked memory (kbytes, -l) 32 max memory size (kbytes, -m) unlimited open files (-n) 1024 打开的文件个数限制 pipe size (512 bytes, -p) 8 管道大小的限制 POSIX message queues (bytes, -q) 819200 消息队列大小 real-time priority (-r) 0 stack size (kbytes, -s) 10240 栈大小 cpu time (seconds, -t) unlimited CPU时间使用限制 max user processes (-u) 27955 zui大的用户进程数限制 virtual memory (kbytes, -v) unlimited 虚拟内存限制 file locks (-x) unlimited 2)测试硬盘速度
安装:
[root@localhost ~]# yum -y install hdparm [root@localhost ~]# hdparm -T -t /dev/sda /dev/sda: Timing cached reads: 3850 MB in 2.00 seconds = 1926.60 MB/sec #2秒中直接从内存的 cache读取数据的速度读 3850 MB。 平均1926.60 MB/sec Timing buffered disk reads: 50 MB in seconds = 13.17 MB/sec #3.80秒中从硬盘缓存中读 50 MB。 seconds = 13.17 MB/sec参数:
-t perform device read timings #不使用预先的数据缓冲, 标示了Linux下没有任何文件系统开销时磁盘可以支持多快的连续数据读取。 -T perform cache read timings #直接从内存的 cache读取数据的速度。实际上显示出被测系统的处理器缓存和内存的吞吐量。3)测试硬盘写
命令: dd
在使用前首先了解两个特殊设备:
/dev/null 伪设备,回收站.写该文件不会产生IO开销 /dev/zero 伪设备,会产生空字符流,读该文件不会产生IO开销测试磁盘的IO写速度:
[root@localhost ~]# dd if=/dev/zero of=/test.dbf bs=8k count=3000 3000+0 records in 3000+0 records out 24576000 bytes (25 MB) copied, 1.04913 s, 23.4 MB/s可以看到,在1.1秒的时间里,生成25M的一个文件,IO写的速度约为122.6MB/sec;
当然这个速度可以多测试几遍取一个平均值,符合概率统计。
执行命令并计时:
[root@localhost ~]# time dd if=/dev/zero of=/test.dbf bs=8k count=3000 3000+0 records in 3000+0 records out 24576000 bytes (25 MB) copied, 1.04913 s, 23.4 MB/s real 0m1.061s 12:00 出去吃饭 user 0m0.002s 路上 20分 sys 0m0.770s 吃10分钟说明:
1) 实际时间(real time): 从command命令行开始执行到运行终止的消逝时间;
2) 用户CPU时间(user CPU time): 命令执行完成花费的用户CPU时间,即命令在用户态中执行时间总和;
3) 系统CPU时间(system CPU time): 命令执行完成花费的系统CPU时间,即命令在核心态中执行时间总和。
其中,用户CPU时间和系统CPU时间之和为CPU时间,即命令占用CPU执行的时间总和。实际时间要大于CPU时间,因为Linux是多任务操作系统,往往在执行一条命令时,系统还要处理其它任务。排队时间没有算在里面。
另一个需要注意的问题是即使每次执行相同命令,但所花费的时间也是不一样,其花费时间是与系统运行相关的。
4、网络性能调优
1)网卡绑定技术 /双线冗余
网卡绑定及简单原理:
网卡绑定也称作"网卡捆绑",就是使用多块物理网卡虚拟成为一块网卡,以提供负载均衡或者冗余,增加带宽的作用。当一个网卡坏掉时,不会影响业务。这个聚合起来的设备看起来是一个单独的以太网接口设备,也就是这几块网卡具有相同的IP地址而并行链接聚合成一个逻辑链路工作。这种技术在Cisco等网络公司中,被称为Trunking和Etherchannel 技术,在Linux的内核中把这种技术称为bonding。
2)技术分类
1. 负载均衡
对于bonding的网络负载均衡是我们在文件服务器中常用到的,比如把三块网卡,当做一块来用,解决一个IP地址,流量过大,服务器网络压力过大的问题。为了解决同一个IP地址,突破流量的限制,毕竟网线和网卡对数据的吞吐量是有限制的。如果在有限的资源的情况下,实现网络负载均衡,更好的办法就是 bonding。
2. 网络冗余
对于服务器来说,网络设备的稳定也是比较重要的,特别是网卡。在生产型的系统中,网卡的可靠性就更为重要了。在生产型的系统中,大多通过硬件设备的冗余来提供服务器的可靠性和安全性,比如电源。bonding 也能为网卡提供冗余的支持。把多块网卡绑定到一个IP地址,当一块网卡发生物理性损坏的情况下,另一块网卡自动启用,并提供正常的服务,即:默认情况下只有一块网卡工作,其它网卡做备份。
3)配置多网卡绑定
配置两双网卡,网卡ens33和ens37都桥接。
添加网卡:
[root@localhost ~]# cd /etc/sysconfig/network-scripts/ [root@localhost network-scripts]# ls ifcfg-ens3* ifcfg-ens33 ifcfg-ens37网卡绑定模式:active-backup - 主备模式。
一个网卡处于活跃状态,另一个处于备份状态,所有流量都在主链路上处理,当活跃网卡down掉时,启用备份网卡。
绑定网卡:ens33+ens37=bond0
设置网卡ens33为主网卡(优先处于活跃状态),ens37为辅网卡(备份状态,主网卡链路正常时,辅网卡处于备份状态)。
查看物理网卡信息:
[root@localhost ~]# nmcli device 设备 类型 状态 连接 virbr0 bridge 连接的 virbr0 ens33 ethernet 连接的 ens33 ens37 ethernet 连接的 ens37 [root@localhost ~]# nmcli connection show 名称 UUID 类型 设备 ens33 7cd11800-7199-4cae-8927-ec49303cfe52 802-3-ethernet ens33 ens37 605551ec-6f72-368f-a5f5-cf2ae3fedd45 802-3-ethernet ens37删除网卡连接信息:本次Network bonding配置中,需要将ens33和ens37绑定为bond0,并且设置ens33为主网卡,首先需要这两块网卡现有的配置信息,否则team0创建完成后,未删除的网卡配置信息会影响bond0的正常工作。
如果nmcli connection show命令输出中无将要进行配置的网卡连接信息,则无需进行删除操作。
[root@localhost network-scripts]# nmcli connection delete ens33 成功删除连接 'ens33'(7cd11800-7199-4cae-8927-ec49303cfe52)。 [root@localhost network-scripts]# nmcli connection delete ens37 成功删除连接 'ens37'(605551ec-6f72-368f-a5f5-cf2ae3fedd45)。 [root@localhost network-scripts]# nmcli connection show 名称 UUID 类型 设备 virbr0 0c6bda20-636e-4555-a5eb-10ebffc43c38 bridge virbr0 有线连接 1 33136afd-2e13-310d-9c9d-cf4858545cf0 802-3-ethernet ens33 有线连接 2 3b9c673a-53eb-3f0c-91ae-1b63015ec734 802-3-ethernet ens37网卡连接信息删除成功,这里删除的其实就是/etc/sysconfig/network-scripts目录下两块网卡的配置文件。
[root@localhost network-scripts]# pwd /etc/sysconfig/network-scripts [root@localhost network-scripts]# ls ifcfg-* ifcfg-lo [root@localhost network-scripts]# nmcli connection add type bond ifname bond0 con-name bond0 miimon 100 mode active-backup primary ens33 ip4 192.168.1.63/24连接“bond0”(d558d571-3171-4a8d-b71c-2ff04aca68c1) 已成功添加。
说明:
primary ens33:指定主网卡为ens33 mode active-backup:指定bonding模式为active-backup(主动备份) miimon 100:以毫秒为单位指定 MII 链接监控的频率(默认为0,即关闭此功能;配置miimon参数时,更好从100开始)。 bonding内核模块必须在ifcfg-bondN中的BONDING_OPTS="bonding parameters"中指定,各参数间使用空格分隔,不要在/etc/modprobe.d/bonding.conf和已经弃用的/etc/modprobe.conf文件中指定bonding配置选项。配置完成后,此时会在/etc/sysconfig/network-scripts目录下生成ifcfg-bond0的配置文件:
[root@localhost network-scripts]# cat ifcfg-bond0 DEVICE=bond0 BONDING_OPTS="miimon=100 mode=active-backup primary=ens33" TYPE=Bond BONDING_MASTER=yes PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=none IPADDR=192.168.0.63 PREFIX=24 DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=bond0 UUID=d558d571-3171-4a8d-b71c-2ff04aca68c1 ONBOOT=yes将网卡ens33和ens37创建为bond0的子接口:
添加网卡ens33:设备类型:bond-slave;连接名称:bond0-p1;master:bond0。
[root@localhost network-scripts]# nmcli connection add type bond-slave ifname ens33 con-name bond0-p1 master bond0 连接“bond0-p1”(fd76468d-a644-4f5f-855f-fbbc859f440a) 已成功添加添加网卡ens37:设备类型:bond-slave;连接名称:bond0-p2;master:bond0
[root@localhost network-scripts]# nmcli connection add type bond-slave ifname ens37 con-name bond0-p2 master bond0 连接“bond0-p2”(39d983d3-1549-4fc0-bc4b-392d52a8e24e) 已成功添加[root@localhost network-scripts]# cat ifcfg-bond0-p1 TYPE=Ethernet NAME=bond0-p1 UUID=fd76468d-a644-4f5f-855f-fbbc859f440a DEVICE=ens33 ONBOOT=yes MASTER=bond0 SLAVE=yes [root@localhost network-scripts]# cat ifcfg-bond0-p2 TYPE=Ethernet NAME=bond0-p2 UUID=39d983d3-1549-4fc0-bc4b-392d52a8e24e DEVICE=ens37 ONBOOT=yes MASTER=bond0 SLAVE=yes查看当前已激活的网络接口:
[root@localhost network-scripts]# nmcli connection show --active 名称 UUID 类型 设备 bond0 d558d571-3171-4a8d-b71c-2ff04aca68c1 bond bond0 virbr0 0c6bda20-636e-4555-a5eb-10ebffc43c38 bridge virbr0 有线连接 1 33136afd-2e13-310d-9c9d-cf4858545cf0 802-3-ethernet ens33 有线连接 2 3b9c673a-53eb-3f0c-91ae-1b63015ec734 802-3-ethernet ens37如果bond0-p1、bond0-p2、bond0没有激活,可使用下面命令进行激活:
[root@localhost network-scripts]# nmcli connection up bond0-p1 连接已成功激活(D-Bus:/org/freedesktop/NetworkManager/ActiveConnection/9) [root@localhost network-scripts]# nmcli connection up bond0-p2 连接已成功激活(D-Bus:/org/freedesktop/NetworkManager/ActiveConnection/10) root@localhost network-scripts]# nmcli connection up bond0 成功激活(主服务器等待从服务器)连接(/org/freedesktop/NetworkManager/ActiveConnection/11)查看bond0当前状态:
[root@localhost network-scripts]# cd /proc/net/bonding/ [root@localhost bonding]# ls bond0 [root@localhost bonding]# cat bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: fault-tolerance (active-backup) Primary Slave: ens33 (primary_reselect always) Currently Active Slave: ens33 //当前所使用的接口 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Slave Interface: ens33 //从接口 MII Status: up //状态为开启 Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:0c:29:72:33:db Slave queue ID: 0 Slave Interface: ens37 //从接口 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:0c:29:72:33:e5 Slave queue ID: 0bonding切换测试:
[root@localhost bonding]# ping 192.168.1.1 PING 192.168.0.1 (192.168.0.1) 56(84) bytes of data. 64 bytes from 192.168.0.1: icmp_seq=1 ttl=64 time=2.35 ms 64 bytes from 192.168.0.1: icmp_seq=2 ttl=64 time=1.41 ms 64 bytes from 192.168.0.1: icmp_seq=3 ttl=64 time=1.01 ms [root@localhost bonding]# nmcli connection down bond0-p1 成功取消激活连接 'bond0-p1'(D-Bus:/org/freedesktop/NetworkManager/ActiveConnection/12) [root@localhost bonding]# ping 192.168.1.1 //停止了bond0-p1,仍然可以Ping通过 PING 192.168.0.1 (192.168.0.1) 56(84) bytes of data. 64 bytes from 192.168.0.1: icmp_seq=1 ttl=64 time=0.922 ms 64 bytes from 192.168.0.1: icmp_seq=2 ttl=64 time=0.604 ms 64 bytes from 192.168.0.1: icmp_seq=3 ttl=64 time=0.551 ms停止bond0-p1网卡,再次查看bond0状态:
[root@localhost bonding]# cat bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: ens37 //原来的接口为ens33,目前变为ens37 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Slave Interface: ens37 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:0c:29:72:33:e5 Slave queue ID: 0以上是直接停止bond0-p1接口,如果是直接在虚拟机中断开网卡的连接,那么在bond0信息中则会看到bond0-p1为down的信息。
[root@localhost bonding]# nmcli connection up bond0-p1 //再次启动bond0-p1接口 连接已成功激活(D-Bus:/org/freedesktop/NetworkManager/ActiveConnection/15) [root@localhost bonding]# cat bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: fault-tolerance (active-backup) Primary Slave: ens33 (primary_reselect always) Currently Active Slave: ens33 //此时的ens33成为了当前使用的接口 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Slave Interface: ens37 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:0c:29:72:33:e5 Slave queue ID: 0 Slave Interface: ens33 MII Status: up Speed: 1000 Mbps Duplex: full Link Failure Count: 0 Permanent HW addr: 00:0c:29:72:33:db Slave queue ID: 0添加网关:
[root@localhost network-scripts]# vim ifcfg-bond0 GATEWAY=192.168.0.1 [root@localhost network-scripts]# service network restart Restarting network (via systemctl): [ 确定 ] [root@localhost network-scripts]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.0.1 0.0.0.0 UG 300 0 0 bond0 192.168.0.0 0.0.0.0 255.255.255.0 U 300 0 0 bond0 192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0添加DNS:
[root@localhost bonding]# vim /etc/resolv.conf nameserver 114.114.114.114 [root@localhost network-scripts]# curl -I www.baidu.com HTTP/1.1 200 OK Server: bfe/1.0.8.18 Date: Thu, 18 Jan 2018 17:00:30 GMT Content-Type: text/html Content-Length: 277 Last-Modified: Mon, 13 Jun 2016 02:50:04 GMT Connection: Keep-Alive ETag: "575e1f5c-115" Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform Pragma: no-cache Accept-Ranges: bytes5、内核参数性能调优
1)抵御SYN
SYN攻击是利用TCP/IP协议3次握手的原理,发送大量的建立连接的网络包,但不实际建立连接,zui终导致被攻击服务器的网络队列被占满,无法被正常用户访问。
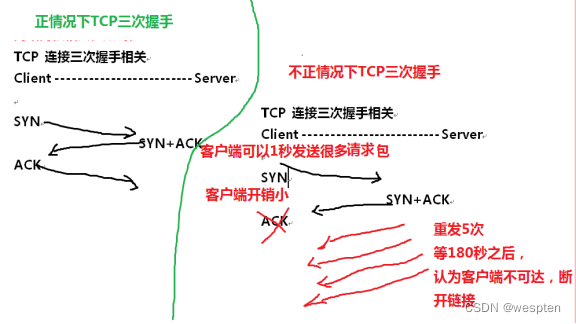
SYN Flood是当前zui流行的DoS(拒绝服务攻击)与DDoS(分布式拒绝服务攻击)的方式之一,这是一种利用TCP协议缺陷,发送大量伪造的TCP连接请求,常用假冒的IP或IP段发来海量的请求连接的第一个握手包(SYN包),被攻击服务器回应第二个握手包(SYN+ACK包),因为对方是假冒IP,对方永远收不到包且不会回应第三个握手包。导致被攻击服务器保持大量SYN_RECV状态的“半连接”,并且会重试默认5次回应第二个握手包,塞满TCP等待连接队列,资源耗尽(CPU满负荷或内存不足),让正常的业务请求连接不进来。
解决:
[root@localhost ~]# vim /etc/sysctl.conf #在文件zui后添加以下内容 net.ipv4.tcp_synack_retries = 0 net.ipv4.tcp_syn_retries = 1 net.ipv4.tcp_max_syn_backlog = 20480 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 10 fs.file-max = 819200 net.core.somaxconn = 65536 net.core.rmem_max = 1024123000 net.core.wmem_max = 16777126 net.core.netdev_max_backlog = 165536 net.ipv4.ip_local_port_range = 10000 65535每台服务器上线之前,都应该配置以上内核参数。
zui重要参数:
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_synack_retries #zui关键参数,默认为5,修改为0 表示不要重发 net.ipv4.tcp_synack_retries = 0表示回应第二个握手包(SYN+ACK包)给客户端IP后,如果收不到第三次握手包(ACK包)后,不进行重试,加快回收“半连接”,不要耗光资源。
作为服务端。回应时,如果连接失败,达到对应的失败数后,停止发送synack包
第一个参数tcp_synack_retries = 0是关键,表示回应第二个握手包(SYN+ACK包)给客户端IP后,如果收不到第三次握手包(ACK包)后,不进行重试,加快回收“半连接”,不要耗光资源。
不修改这个参数,模拟攻击,10秒后被攻击的80端口即无法服务,机器难以ssh登录; 用命令netstat -na |grep SYN_RECV检测“半连接”hold住180秒。
修改这个参数为0,再模拟攻击,持续10分钟后被攻击的80端口都可以服务,响应稍慢些而已,只是ssh有时也登录不上;检测“半连接”只hold住3秒即释放掉。
修改这个参数为0的副作用:网络状况很差时,如果对方没收到第二个握手包,可能连接服务器失败,但对于一般网站,用户刷新一次页面即可。这些可以在高峰期或网络状况不好时tcpdump抓包验证下。
根据以前的抓包经验,这种情况很少,但为了保险起见,可以只在被tcp洪水攻击时临时启用这个参数。
tcp_synack_retries默认为5,表示重发5次,每次等待30~40秒,即“半连接”默认hold住大约180秒。
我们之所以可以把tcp_synack_retries改为0,因为客户端还有tcp_syn_retries参数,默认是5,即使服务器端没有重发SYN+ACK包,客户端也会重发SYN握手包。
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_syn_retries tcp_syn_retries参数,默认是5,当没有收到服务器端的SYN+ACK包时,客户端重发SYN握手包的次数,注意:在rhel 7中,此项不能调为0。
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_max_syn_backlog 20480半连接队列长度,增加SYN队列长度到20480:加大SYN队列长度可以容纳更多等待连接的网络连接数,具体多少数值受限于内存。
接下来辅助参数:
#系统允许的文件句柄的zui大数目,因为连接需要占用文件句柄。 fs.file-max = 819200 #用来应对突发的大并发connect 请求 net.core.somaxconn = 65536 #zui大的TCP 数据接收缓冲(字节) net.core.rmem_max = 1024123000 #zui大的TCP 数据发送缓冲(字节) net.core.wmem_max = 16777126 #网络设备接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的zui大数目 net.core.netdev_max_backlog = 165536 #本机主动连接其他机器时的端口分配范围,比如说,在vsftpd主动模式会用到 net.ipv4.ip_local_port_range = 10000 65535如果只是开启22端口,是不会使用到ip_local_port_range这个功能
[root@localhost ~]# netstat -antup | grep :22 tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1993/sshd tcp 0 0 192.168.1.63:22 192.168.1.23:51855 ESTABLISHED 9316/sshd tcp 0 0 192.168.1.63:22 192.168.1.23:51861 ESTABLISHED 10878/sshd 为了处理大量连接,还需限制用户资源配置文件:
[root@localhost ~]#vim /etc/security/limits.conf #在zui添加: * soft nofile 1024000 * hard nofile 1024000 用户可以打开的zui大进程数:[root@localhost ~]# vim /etc/security/limits.d/90-nproc.conf #RHEL6 必须这个文件中配置 改: * soft nproc 10240 为: * soft nproc 66666 * hard nproc 66666 [root@localhost ~]# reboot #更好重启一下次要辅助参数,以上还无法解决syn洪水攻击,把以下内核参数关闭:
#当出现 半连接 队列溢出时向对方发送syncookies,调大半连接队列后没必要 net.ipv4.tcp_syncookies = 0 #TIME_WAIT状态的连接重用功能 net.ipv4.tcp_tw_reuse = 0 #时间戳选项,与前面net.ipv4.tcp_tw_reuse参数配合 net.ipv4.tcp_timestamps = 0 #TIME_WAIT状态的连接回收功能 net.ipv4.tcp_tw_recycle = 0注意,以下参数面对外网时,不要打开,因为副作用很明显。
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_syncookies 1表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_tw_reuse 1表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭,现在开启,改为1
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_tw_recycle 1表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。现在改为1,表示开启
[root@localhost ~]# cat /proc/sys/net/ipv4/tcp_fin_timeout 10默认值是 60,对于本端断开的socket连接,TCP保持在FIN_WAIT_2状态的时间。
调整MTUzui大传输单元:
[root@localhost ~]# ifconfig ens33 mtu 9000MTU,即Maximum Transmission Unit(zui大传输单元),此值设定TCP/IP协议传输数据报时的zui大传输单元。
系统与ISP之间MTU的不符就会直接导致数据在网络传输过程中不断地进行分包、组包,浪费了宝贵的传输时间,也严重影响了宽带的工作效率。
以上内容由“WiFi之家网”整理收藏!。

评论